Artificial intelligence isn’t magical. When you ask it to write an email, letter to the editor, or a full article, it’s getting the content from somewhere. Some major sites, like the New York Times, are saying no thank you to Apple Intelligence, not wanting them to use web scraping on their content to train the AI.
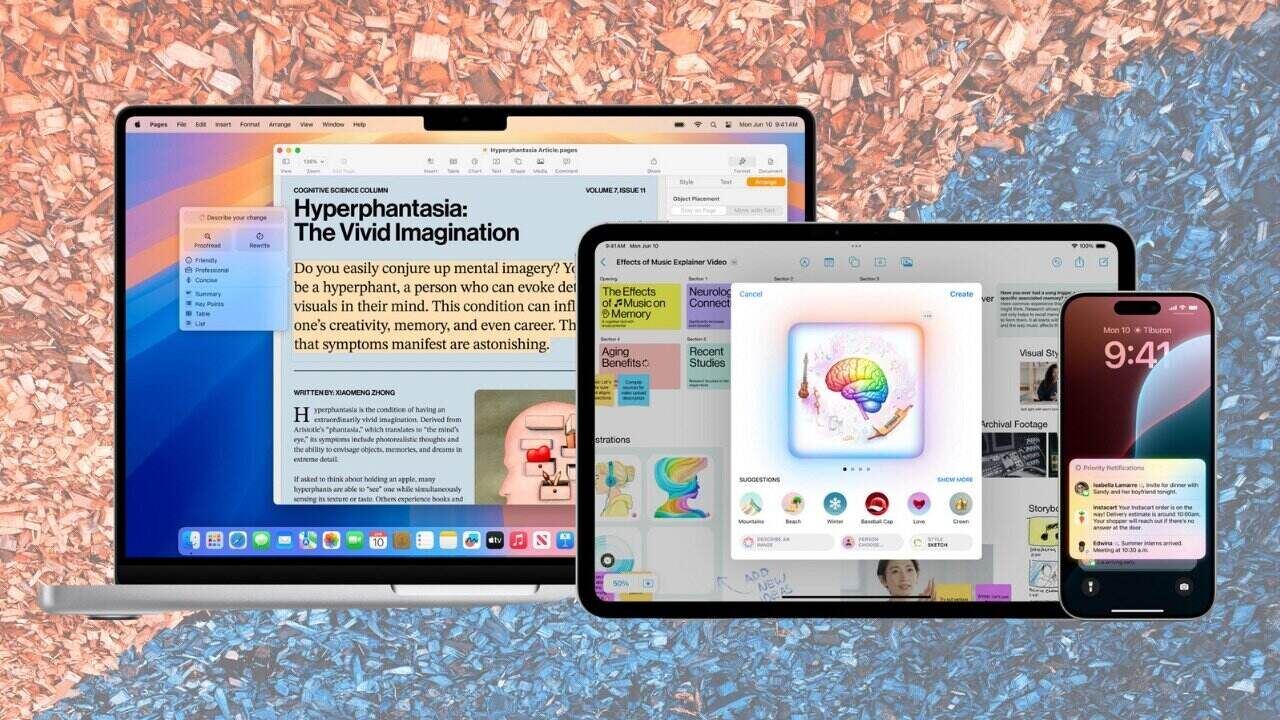
Apple Intelligence
There have been many things said about Apple Intelligence, and it hasn’t even been officially released yet, as iOS 18 will make its debut next month. Even then, it won’t be fully ready. Only a few of the features have been released in the developer beta version for iOS 18.1. Additionally, only the newest iPad Pros and newest iPhone Pros can use it. Although, when the iPhone 17 debuts next month, the whole series is expected to work with Apple Intelligence.

Apple Intelligence is the Cupertino tech company’s own artificial intelligence. It still must be trained with AI web scraping to be able to provide its many services.
AI web scraping is the automated process of collecting data from websites using artificial intelligence technologies. It involves using AI algorithms to extract, analyze, and structure information from web pages for various purposes, such as training AI models like Apple Intelligence or gathering large datasets.
Sites Won’t Allow Apple’s AI Web Scraping
Despite the fact that all AI chatbots have to train in this manner, and Apple Intelligence is not even ready for a full release in beta, multiple websites are already putting the block on Apple. If you’re worried about your own website, we can show you how to protect your website from AI web scraping.
This could hurt Apple Intelligence, as the sites that are shutting it down are important content providers: Facebook, Instagram, Craigslist, Tumblr, The New York Times, The Financial Times, The Atlantic, Vox Media, the USA Today network, and Condé Nast.
The important part of the equation is that Apple Intelligence isn’t secretly scraping websites. In fact, it provides a way for websites to opt out. Yet, they may not have been expecting so many to opt out – before it’s even released.
Web scraping isn’t new – it’s been around for some time. However, being attached to artificial intelligence is new, and perhaps that is what is leading to the uneasiness of the websites.
Apple’s specific AI web crawler is “Applebot-Extended.” The initial Applebot was introduced in 2015 and was used to provide data for Siri and Spotlight. It needed a different web crawler, though, for Apple Intelligence. Applebot-Extended does not stop the Apple bot. Instead, it doesn’t allow the data to be used to train Apple’s LLM (large language models).
Apple is not necessarily being singled out here. AI bots from OpenAI, Anthropic, and other AI content heavyweights have been blocked as well. While Apple has been blocked much less, again, it’s still new and hasn’t even made its official debut. It seems unlikely that websites just trust Apple more.
If you’re looking to collect your own data, check out these great AI web scraping tools that anyone can use. Also, check out our review of Octoparse for an easy way to scrape the web.
Image credit: Apple






